Analysis of the axpby and dot routines
Contents
Analysis of the axpby and dot routines¶
import numpy as np
from collections import OrderedDict as odict
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.cm as cm
Here is a list of all the file(ending)s and an indication of the corresponding architecture and number of nodes. Also we define some utilities that we use in our plot further down:
#(hardware name, number of nodes)
files = odict({})
files['i5'] = ('i5',1)
files['gtx1060'] = ('gtx1060',1)
files['skl_mpi1'] = ('skl',1)
files['skl_mpi2'] = ('skl',2)
files['skl_mpi4'] = ('skl',4)
files['knl_mpi1'] = ('knl',1)
files['knl_mpi2'] = ('knl',2)
files['knl_mpi4'] = ('knl',4)
files['p100nv_mpi1'] = ('p100',1)
files['p100nv_mpi2'] = ('p100',2)
files['p100nv_mpi4'] = ('p100',4)
files['v100nv_mpi1'] = ('v100',1)
files['v100nv_mpi2'] = ('v100',2)
files['v100nv_mpi4'] = ('v100',4)
# order by number of nodes to make labeling easier further down
files=odict(sorted(files.items(), key= lambda t : t[1][1]))
# count number of 1 nodes in dict
number=0
for k,v in files.items():
if v[1]==1: number+=1
#setup plotting specifications
arch = {'knl':(cm.Greens,450,0.7),'skl':(cm.Greys,205,0.7),'p100':(cm.Blues,550,0.7),'v100':(cm.Purples,850,0.7),
'i5':(cm.Wistia,30,0.5),'gtx1060':(cm.Oranges,157,0.5)}
intens={1:0.8, 2:0.6, 4:0.4}
In the next box we read in all files defined previously and take only the axpby and dot columns. For these we compute the average bandwidth for each row and then plot.
for q in ('axpby','dot'):
fig,ax=plt.subplots(1,1,figsize=(6,3.7),dpi= 80, facecolor='w', edgecolor='k')
for f, v in files.items():
#read in csv file
df=pd.read_csv('benchmark_'+f+'.csv', delimiter=' ')
#add size and get rid of non-relevant columns
df.insert(0,'size', 8*df['n']*df['n']*df['Nx']*df['Ny']/1e6/v[1])
bw = df[['n','Nx','Ny','size']]
bw = bw.assign(axpby = df['size']/1000*3/df['axpby'])
bw = bw.assign(dot = df['size']/1000*2/df['dot'])
#compute mean and standard derivation of 'same' groups
bw=bw.groupby(['n', 'Nx','Ny','size']).agg(['mean', 'std'])
bw.reset_index(level=['n','Nx','Ny','size'], inplace=True)
#add to plot
toPlot = bw[q].join(bw[('size')])
toPlot.plot(ax=ax,color=arch[v[0]][0](intens[v[1]]), marker='o',ls='',markeredgecolor='k',
x='size',y='mean',markersize=8,label=v[0])#+' ('+str(arch[v[0]][1])+')')
plt.xlabel('array size [MB] / # of nodes')
plt.xscale('log')
plt.yscale('log')
plt.xlim(1e-1,1e3)
#for k,v in arch.items():
# if q=='axpby' :
# plt.axhline(y=v[1],xmin=v[2],xmax=1,color=v[0](1.0),lw=2)
handles, labels = plt.gca().get_legend_handles_labels()
handles = handles[0:number]; labels = labels[0:number]
if q=='dot':
plt.legend(handles, labels, loc='upper left',numpoints=1,ncol=2,
fontsize='medium',framealpha=0.5)
plt.ylabel('throughput [GB/s] / # of nodes')
plt.ylim(1,1e4)
else:
plt.legend(handles, labels, loc='lower left',ncol=2,numpoints=1,
fontsize='medium',framealpha=0.5)
plt.ylabel('throughput [GB/s] / # of nodes')
plt.ylim(1,1e4)
#plt.title(q)
plt.savefig(q+'.pdf',bbox_inches='tight')
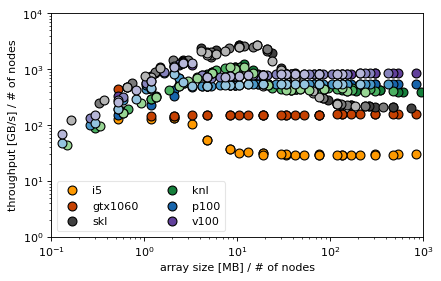
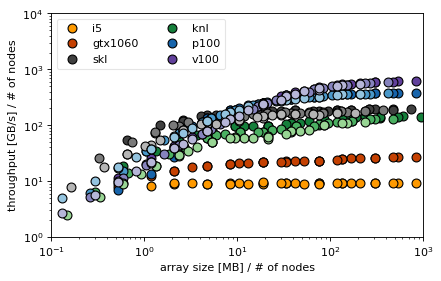
intensity marks number of nodes: darkest 1 node, ligthest 4 nodes
Conclusions¶
the linear increase in bandwidth with size is the latency dominated regime
for dot GPU has high latency because it sends result to CPU, but why the KNL card?
GPUs have smallest latencies in axpby, KNL highest
bandwidth dominated regime starts at around 10MB
especially in Skylake the cache effect in axpby is obvious: without communication vector just stays in cache of size 33MB
total problem size on one node in both axpby and dot is 2 * array size
size normalization for MPI reveals that it is indeed the single node bandwidth that counts, (if we simply divided bandwidth by # of nodes, we would falsely attribute performance loss to MPI communication)
for small sizes the communication overhead in MPI becomes visible
Skylake achieves almost 100% efficiency in dot product, followed by Tesla cards P100 and V100